This post is part of the 2022 C# Advent, an annual showcase of new C# content on the web. Thanks very much to Matt Groves for creating a space for us to share with the community!
Let's build a parser for a template language #
Writing code to parse a language may not be quite as extraordinary as writing a compiler but it's still a very handy capability!
In this post, I'm going to begin writing a parser for a simple templating language that I plan to use in a future project. Eventually it may look vaguely like Nunjucks.
I'll set up a quick C# solution, and some logic to parse simple expressions of the templating language. Specifically, I want to read in some arbitrary templating code and build a parse tree. A parse tree represents in memory the logical structure of the templating code. Then, my program can do... whatever it was going to do with that templating code in the first place!
The templating language #
The proto version of our templating language will be quite simple. Here's a sample statement:
{{ me.addresses["home"].city }}
The double curly braces indicate the opening of "template space". Inside this space we can have an identifier. The identifier can be as simple as one variable name like me or myValue, or it can use the dot . notation to indicate a property relationship (for example: me.addresses indicates that addresses is a property of me.)
We can also use the square brackets after a property name to indicate that a certain property is actually an index of other values. In our case above, addresses represents a collection of addresses that are indexed by name. So the above example could be understood as "My home address's city".
The parse tree #
Parsing the above sample would yield a parse tree like this:
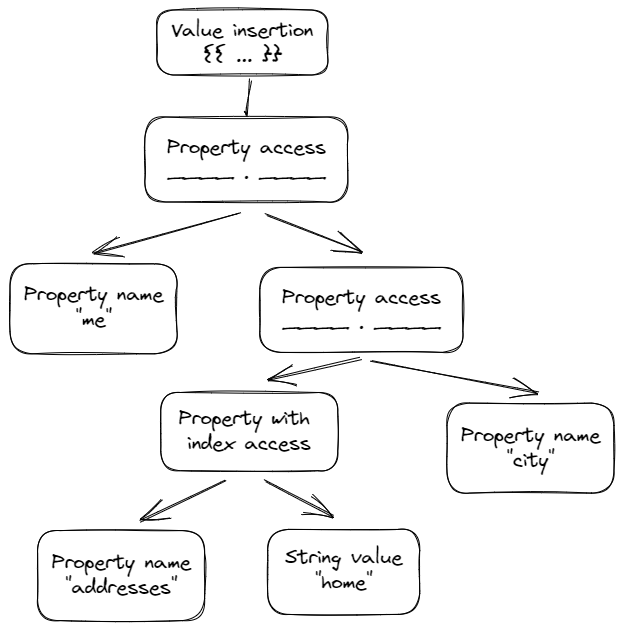
The code project #
All the code for this post is in this GitHub repo - use the blog-post branch as linked to see the version of the code that was current as of this article, but going forward I may continue to update this parser and add more capabilities - for latest, see master branch.
Characteristics #
The project is in .NET 7, and makes use of the Pidgin library (see NuGet package Pidgin).
The Pidgin parser combinator #
For this post, I decided to explore a parser tool I had not yet tried. I've previously done some work in ANTLR, which is widely recognized as a feature-rich industry standard. However, generating a C# parser using ANTLR is a multi-step task, involving the ANTLR executable (which runs on Java) and the creation of lexer and parser grammar files in the Backus-Naur Form.
However I still need a real parser - mere regular expressions are not adequate for a real language where recursive grammar is possible; they are best for matching simple non-recursive patterns only.
In researching this project, I learned of a third type of parser called a parser combinator, basically it's a way to compose big parsers out of smaller parsers using only code! No complicated executables or pre-processors required.
I had already heard of a tool called Sprache that falls into this class, but in researching my options, I was impressed by the advantages that the Pidgin parser combinator had to offer, so that's what I've used here.
The code #
Let's look at snippets of the code itself. It's important to note that in the version that's current as of this post, I only have support for parsing a small subset of the template language.
Here's what it will parse, currently:
- A value insertion that looks like
{{ some.value }} - Within that value insertion it can handle identifiers on the order of the sample one posted above:
me.addresses["home"].city. In other words, in can handle the dot notation, nested property accessors, and index references with square brackets.
There would be a lot more types of expressions to parse in a complete Nunjucks-like template language parser. I do plan on making more updates to the master branch eventually.
Parse tree classes #
I created a family of classes to represent the different types of nodes in the parse tree (see diagram above).
A sampling:
public abstract class Node : IEquatable<Node>
{
// The IEquatable capability is for deep parse tree comparison in the test code.
public abstract bool Equals(Node? other);
public override bool Equals(object? obj) => Equals(obj as Node);
public abstract override int GetHashCode();
}
public abstract class Expr : Node
{
}
public abstract class Identifier : Expr
{
}
public class CodeName: Identifier
{
public string Name { get; }
public CodeName(string name)
{
Name = name;
}
public override bool Equals(Node? other)
=> other is CodeName cn && Name == cn.Name;
public override int GetHashCode() => Name.GetHashCode(StringComparison.Ordinal);
}
public class IdentifierSegment: Identifier
{
public CodeName CodeName { get; }
public Expr? Index { get; }
public IdentifierSegment(CodeName codeName, Expr? index = null)
{
CodeName = codeName;
Index = index;
}
public override bool Equals(Node? other)
=> other is IdentifierSegment seg
&& CodeName.Equals(seg.CodeName)
&& (
(Index == null && seg.Index == null)
|| (Index != null && seg.Index != null && Index.Equals(seg.Index))
);
public override int GetHashCode() => HashCode.Combine(CodeName, Index);
}
public class PropertyAccess: Identifier
{
public IdentifierSegment Segment { get; }
public Identifier PropertyRef { get; }
public PropertyAccess(IdentifierSegment segment, Identifier propertyRef)
{
Segment = segment;
PropertyRef = propertyRef;
}
public override bool Equals(Node? other)
=> other is PropertyAccess pa && Segment.Equals(pa.Segment) && PropertyRef.Equals(pa.PropertyRef);
public override int GetHashCode() => HashCode.Combine(Segment, PropertyRef);
}All the parse tree classes can be seen in the NunjucksParser.Model project.
Parser logic #
The parser logic uses Pidgin primitives to build larger parsers out of smaller ones. Let's look at some sample code:
private static readonly Parser<char, Node> _identifierSegment =
OneOf(
// Case of code name with index access [...]
Try(
Map(
(codeName, _, index, _) => new IdentifierSegment(codeName as CodeName, index as Expr) as Node,
_codeName,
Char('['),
ExprParser.Expr,
Char(']')
)
),
// Case of plain code name without index access
_codeName.Select(codeName => new IdentifierSegment(codeName as CodeName) as Node)
)
.Labelled("identifier segment");The above logic declares the rules for parsing an "identifier segment", which is essentially a code name that may or may not be followed by a square-bracket index reference. A successful parse operation, as shown, will result in a new instance of the parse tree class IdentifierSegment being created and returned.
The following from our example are all examples of identifier segments:
meaddresses["home"]city
The code identifiers above _codeName and ExprParser.Expr are all references to other parsers that have been constructed and can now be composed into the larger parser.
All of the Pidgin-powered parsing logic can be found in the NunjucksParsers.Pidgin project.
Unit tests #
In the unit test project, I run the parser on various experimental inputs and do a deep compare of the resulting parse tree with the one I'd expect to get.
Here's a snippet of some of the test code:
public class TemplateParserTests
{
public static IEnumerable<object[]> Cases =>
new List<object[]>
{
new object[]
{
true,
// Input to be parsed
"{{ foo }}",
// Expect this parse tree as a result.
new ValueInsertion(
new IdentifierSegment(
new CodeName("foo")
)
)
},
new object[]
{
true,
// Input to be parsed
"{{ me.addresses[\"home\"].city }}",
// Expect this parse tree as a result.
new ValueInsertion(
new PropertyAccess(
new IdentifierSegment(
new CodeName("me")
),
new PropertyAccess(
new IdentifierSegment(
new CodeName("addresses"),
new StringLiteral("home")
),
new IdentifierSegment(
new CodeName("city")
)
)
)
)
},
};
[Theory]
[MemberData(nameof(Cases))]
public void ParseOrThrow(bool expectToParse, string input, Node expectedTree)
{
if (expectToParse)
{
var actualTree = TemplateParser.ParseOrThrow(input) as Node;
Assert.True(actualTree.Equals(expectedTree));
}
else
{
Assert.Throws<ParseException>(() => IdentifierParser.ParseOrThrow(input));
}
}
}Further reading #
Thanks for stopping by! If you have suggestions or comments, I'd love to see them below.
Here's more about Pidgin:
- Pidgin main repo
- Pidgin examples by its creator, Benjamin Hodgson
- Pidgin API docs
- Excellent tutorial on Pidgin by Benjamin Hodgson which provided me invaluable insight when working on this post.